RubyでWebページからトピック一覧を取得してみよう。 Mechanize/nokogiri
RubyでWebページからトピック一覧を取得してみよう。 Mechanize/nokogiri
2014年2月20日 1 Comment on RubyでWebページからトピック一覧を取得してみよう。 Mechanize/nokogiriWebページからトピック一覧を引っこ抜くテクニックです。一般的にはスクレイピングと言われるらしいですが、名前はさておき、適当なページからニューストピック一覧なんかを引っこ抜いてみましょう。
浅田真央残念!フリーで挽回できるかなぁ??
下準備
Rubyのgem nokogiriとmechanizeをインストールします。
[bash]
$ gem install nokogiri
$ gem install mechanize
[/bash]
取得対象とするページ
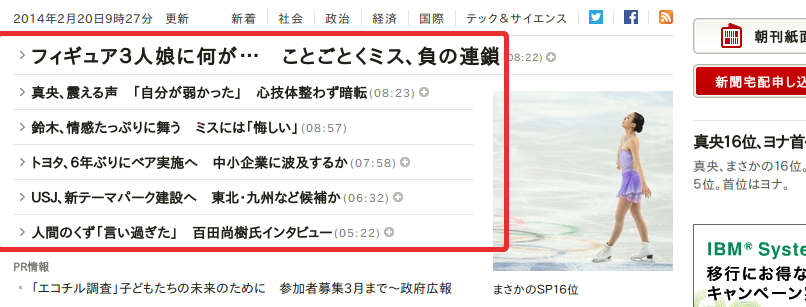
今回は朝日新聞さんのサイトからトピックを抜き取ってみます。赤く囲んだところがターゲットです。

HTMLの構造を目視でチェック
トピック欄のHTMLの構造をチェックし、どんなCSSセレクターで一覧を引っこ抜くことができるかを確認します。今回の場合はクラスList/ListSideImage/ListHeadlineをもつULタグの下に存在する aタグの情報を抜けば良いというのがわかりました。

Rubyのソース
test.rb とか 適当なファイル名で保存してください。
[ruby]
require ‘mechanize’
client = Mechanize.new
url = “http://www.asahi.com”
page = client.get(url)
atags = page.search(“ul.List.ListSideImage.ListHeadline a”)
p atags.length
atags.each do |atag|
p atag.inner_text
end
[/ruby]
トピック一覧取得
さて、ソースを実行してみましょう!
めでたくトピック一覧の取得に成功しました。簡単ですね。
[bash]
$ ruby test.rb
7
“フィギュア3人娘に何が… ことごとくミス、負の連鎖(08:22)”
“まさかのSP16位”
“真央、震える声 「自分が弱かった」 心技体整わず暗転(08:23)”
“鈴木、情感たっぷりに舞う ミスには「悔しい」(08:57)”
“トヨタ、6年ぶりにベア実施へ 中小企業に波及するか(07:58)”
“USJ、新テーマパーク建設へ 東北・九州など候補か(06:32)”
“中国、外国記者に対日宣伝戦 南京案内、国際世論に訴え(09:50)”
[/bash]
Leave a comment